I think the most unusual thing about the physical tone matrix I posted about yesterday is the screen - I hadn't seen one like it before I made it, and having made one I now know why - they're very fiddly to make. I'd like to go into some more details about how it is made and how it works.
Step 1 is to cut out a 6" square piece of 1/8" thick acrylic. I bought a 12"x24" piece from Delvie's plastics (the cheapest shipped price I could find for such a small quantity), which is enough for 8 such screens (though I doubt I'll make another 7 since threading the wire takes so long - I hope I'll be able to make something else fun out of the rest, though). Cutting this stuff is really easy - just score it a few times with a knife and a straightedge where you want it to break, clamp it to a table so that the scored line runs along the edge of the table and then push down hard on the bit that protrudes over the edge of the table - it'll break cleanly along the scored line. Leave the backing paper on for now.
Step 2 is to drill the holes. I deliberated a bit about the hole pattern to use. I originally thought of threading the wires just horizontally and vertically, so that the switch was formed at the place where the two wires "cross over" (but don't quite touch) in the following picture (red is top, blue is bottom):

But then I decided I'd rather have the central point of the switch not have wire over it, so that the LED would be able to shine through at that point. I also realized that I'd be able to make the switches longer (and therefore easier to press) if the wires were arranged diagonally and fairly close to each other. Working backwards from where I wanted the wires to be on the top, I came up with this pattern:
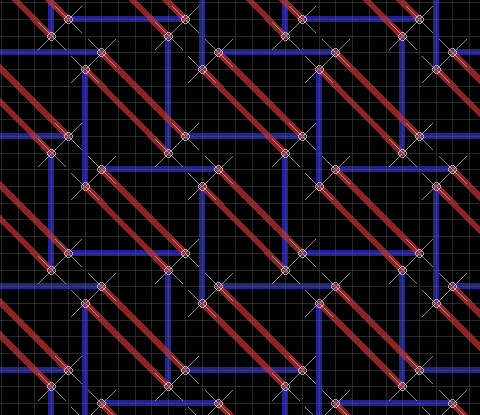
This requires about 67 feet of wire altogether - because of the zig-zagging, each horizontal and vertical wire is about 15" on the matrix itself, with 2" spare on the top, left and right sides and 14" spare on the bottom to connect to the PCB. Use 22AWG solid-core hook-up wire - this should work nicely.
Here is a page showing where all the holes need to be drilled. Print this out and glue it on to one side of the acrylic sheet. Use a drill press to drill all 1,024 holes. I used this which is the cheapest one I could find. It's a bit flimsy but good enough for the purpose (as well as for PCBs, which is what it's meant for). It doesn't quite have enough clearance to reach the center holes if you put it together in the obvious way, but it does come with an attachment which lets you move the drill further away from the metal bar, if you jam a piece of plastic or something in the gap. I used these bits which seemed to work fine. The positioning doesn't have to be perfect but the closer the better. I think I used a number 68 drill bit or thereabouts - make sure your wire fits through the first hole you drill before drilling the rest. The plastic swarf from the drill will accumulate under the glued paper a bit but that doesn't really matter.
While you've got the drill press handy, make a hole of ~2mm diameter in each corner for the screws to hold it onto the PCB. The way I built it, the switch matrix is screwed to the PCB using 1-1/2" long screws and then the PCB is screwed to the bottom box, so the entire thing is rigid (the top of the box also screwed to the bottom of the box - only these screws need to be removed to change the batteries). Choose the positions of these holes carefully, since you will need to make holes in the same position in the PCB.
Step 3 is to remove the backing paper and sand the acrylic on the bottom side using a piece of sandpaper. Shine an LED through it to make sure it's diffusing properly. If you don't sand it the screen will have a very narrow viewing angle (depending on the LEDs used - cheap high brightness ones tend to have a very narrow viewing angle though) and when you can see them they will dazzle you. I think I used a #100 sandpaper or thereabouts - I don't think it matters much but try on a scrap piece first if you're worried. An orbital sander will probably get you a more homogeneous finish, but I just did it by hand (you can see the swirl patterns I made if you look at the screen very closely).
Step 4 is to cut and strip the wire. Cut 16 lengths of wire 19" long and 16 lengths of wire 31" long. Avoid kinking/bending the wire at this stage, to the extent you can. Use wire strippers to strip of all but 2" of insulation from the 19" lengths and all but 14" of insulation from the 31" lengths. You'll need to do this about 6" at a time. You might need to grip the 2" piece of insulation with pliers when stripping the last bit, otherwise you'll remove the wrong bit. Keep the pieces of insulation for step 6.
Step 5 is to thread the wire. Take each piece of wire in turn and thread it into the acrylic, starting at the bottom (31" sections) and the right (19" sections). Push the wire in so that the remaining insulation is right up against the bottom of the acrylic. Follow the pattern carefully - the top wire of each switch goes horizontally and the bottom goes vertically. Bear in mind that the pattern alternates each row, so if you start with the top one in the first row, you'll start with the bottom the second. The PCB has holes for soldering the top and left sides directly underneath the switch matrix, so make sure you pick the alternating pattern that gets it to line up. Make sure none of the wires touch each other - you can always pull them apart slightly with needlenose pliers if they do.
There is a bit of a knack to getting the wires flat and tight with no kinks. Here is how I did it. Suppose you have one segment threaded on the bottom and you're doing the next one on the top side.
a) Thread the loose end of the wire through the next hole. Pull it through. As you are doing so, make sure the wire is in the plane that is perpendicular to the acrylic sheet and that passes through the two holes. If the wire starts to twist over, adjust it so that it is back in this plane. If you don't do this, you'll get a kink in the wire when you pull it tight, which makes it difficult to get it to go where you want it to.
b) get a flat piece of metal (like the side of a pair of pliers) and push against the threaded segment on the bottom. This will prevent the bottom segment from being pushed up in the next step.
c) get another smaller flat piece of metal (like the end of another pair of pliers) and push against the newly threaded segment on the top. Start pushing at the "old" end (bending the wire into a right angle) and work your way along to the "new" end until it's totally flat against the acrylic sheet. If you don't do this there will be slack in the wire which will cause the switches to move when you touch them.
It gets more difficult once you get more of the wires in place, because you've got to navigate around the protruding ends with your flat edges. It might make it easier to do the outermost wires first and then work in towards the middle, but I didn't think that far ahead.
Once I got into practice, it took me about 20 minutes to do each wire, so about 11 hours of threading altogether (this is why I'm not planning to make any more). It's not too bad if you do a couple a day for a couple of weeks - one can carry on a conversation or watch TV at the same time.
Step 6 is to re-insulate the uninsulated loose ends. Cut 1" sections of insulation from the leftovers from step 4 and push them back onto the ends of the wire. If there are any bends or kinks in these parts of the wires you'll have to straighten them out with pliers first. Twist the insulation slightly as you push it back on and it'll go on more easily. This will help avoid short circuits when the circuit is partially assembled and you're testing it.
The switch matrix works by strobing each row and then testing each column. The rows are connected to the output of the "row" 74HC595 shift registers. They are connected via 10K resistors so that if something metal touches the switches they won't cause short out anything. The "active" row (which changes about 1,000 times per second) is brought to logic high (+5V), the others to logic low.
The switch columns are connected (again via 10K resistors) to 74HC4051 analogue multiplexers so that the microcontroller can specify (with three output bits) which of the 8 columns in each half of the matrix it wants to read. This column selection changes 15,625 times per second. The outputs of the two 4051s are connected to Darlington pairs which amplify the signal (which is very weak after it's passed through a finger) and pass it on to two input pins of the microcontroller (one for the left half, one for the right). Immediately after reading these pins, the microcontroller changes the multiplexer selection bits to maximize the time the circuit has to settle into the correct state for the next switch.
The Darlington pair bases are each connected to ground through a capacitor - they won't register as "on" until this capacitor charges up. The larger the capacitor the less sensitive the switches. If the capacitor is too small, you'll get "false on" readings from switches that you aren't actually touching (if the effect could be controlled this might make an interesting proximity sensor sort of input device but it's probably too finicky). If the capacitor is too large then you'll have to press the switches really hard or have damp fingers to for the touch to register.